
More than The Social Graph

Differences between Graphs that Manage Connections on the Internet
“The global mapping of everybody and how they're related.” With these words, the famous programmer Brad Fitzpatrick defined a concept that has become one of the most important elements in the short story of the Internet: the social graph. Few months before, during the first edition of the Facebook Developer Conference (Facebook F8), Mark Zuckerberg had attributed the power of Facebook to the "social graph, the network of connections and relationships between people on the service." Eight years later, the Facebook social graph (The Graph API) is one of the biggest… but it isn’t alone.[caption id="attachment_602" align="aligncenter" width="740"]
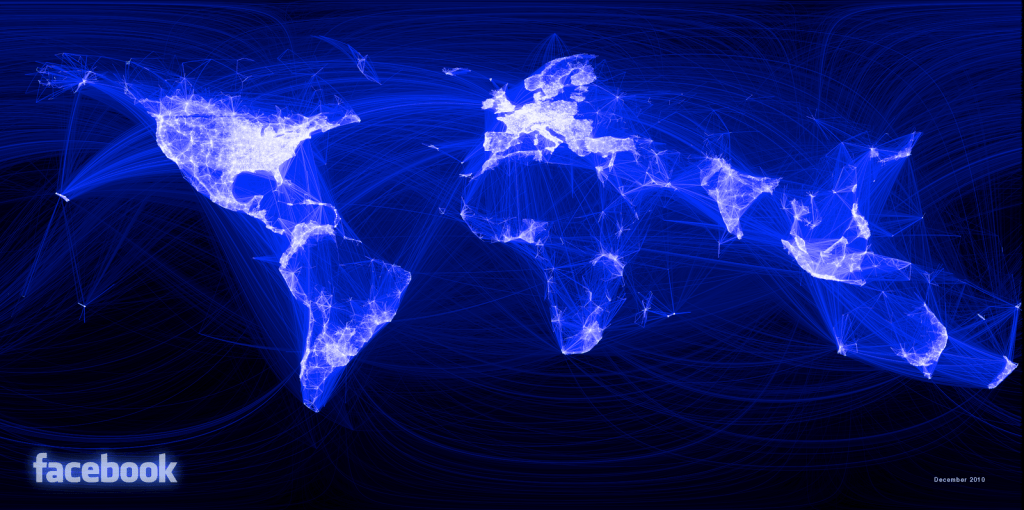
The Facebook social graph is one of the biggest… but it isn’t alone / Visualizing Friendships - Facebook.com[/caption]Any app, game or website offered to customers with a login and friend/follower system has the possibility to store, manage and manipulate user interactions. This opens the possibility to create their own graph.This is a key resource that defines the Internet business. This element allows companies to offer a more accurate product by developing user growth and engagement tactics or applying a business model based on user interactions.
Graphs that Define a World Full of Interactions
Recently, different models of representation have appeared to show how people, places or objects are related. Besides of social graph, these graphs are characterized by the kind of relationships between their nodes, the additional information that they manage or the common connector on which they create relationships.
The Interest Graph
This model clashes or complements with the social graph. While the last term shows the connections based on the type of people's relationships (friends, teammates, family, etc…), the interest graph shows people’s connections based on their interests (objects, places, people, etc…)It’s true that you can show both types of relationships in the same graph. However, the discussion has revolved around connectors. What is the most relevant connector? Which connector has the most value in a social network? The type of people’s relationships or people's interests?From the beginning, the most important social networks (Facebook and Google Plus) had given preference to the social graph model. Even so, they had developed plenty of different features to know the user’s interests too. Facebook continues doing this. The new alternatives to the Facebook's Like button are good examples.[caption id="attachment_603" align="aligncenter" width="600"]

Only Facebook users in Spain and Ireland are currently testing new emojis / Entrepeneur.com[/caption]On the other hand, Google has decided to change Google Plus. A week ago, they launched the new Google Plus searching a new direction to the social network."We are simplifying Google Plus to be a place where people can engage around shared interests. We will move features away that aren’t in line with that focus", a Google spokeswoman said.Likewise, Twitter offers much liberty to users. Thanks to their friend/follower system and the list feature, you can follow people based on your interests and based on your real connections at the same time.Few years after the big social networks were established, other services like Pinterest, Tumblr and Instagram grew quickly, prioritizing people's interest in their network models. Of course, they offer channels for users to invite their friends or contacts too.[caption id="attachment_604" align="aligncenter" width="740"]

Pinterest, Tumblr and Instagram prioritize people's interest in their network models[/caption]The truth is that Facebook, Pinterest and Tumblr are exploiting the value of user’s interests data. On the other hand, Twitter is doing the same, but everybody doesn't think that Twitter is utilizing this resources to their full potential.
The Taste Graph
[caption id="attachment_605" align="aligncenter" width="740"]

"Customers who bought this item also bought". The Taste Graph is used by companies like Amazon / Amazon.com[/caption]This model is similar in many ways to the interest graph. Alan Morrison, a researcher at the Center for Technology and Innovation (CTI), explains in Quora the differences between the two: “An interest graph is (ideally) a superset of graphs and how people, places and things are related. A social graph is a subset of the interest graph, and just depicts relationships between people. A taste graph is just a subset that consists of personal preferences”.In 2011, Harvard researchers proved the true value of the taste graph by showing that we don’t have much influence on our friends’ tastes."The degree to which your friends’ tastes and yours are connected has more to do with how you became friends in the first place than the force of that allegiance later on." When it comes to taste, "peer influence is virtually nonexistent.", said Kevin Lewis (co-authored the study) in a Wired.com reportage. The taste graph is generally used by e-commerce companies like Amazon or Netflix, or in service based on social recommendation networks, by companies like Yelp. This resource is a key element to offer targeted products to users thanks to sophisticated recommendation engines.[caption id="attachment_606" align="aligncenter" width="790"]

Click on the image to open the entire infographic full-size in a new window[/caption]It’s also interesting to remember the story of Hunch.com. Hunch was an American startup that developed a recommendation engine based on tastes and was bought by Ebay for $80M in 2011."eBay buyers are expected to benefit from Hunch’s predictive ability to generate meaningful, yet often non-obvious, recommendations for items available on eBay based on their specific tastes", explains Michael Arrington, the founder of TechCrunch, in his blog.
The Knowledge Graph
This concept comes from Mountain View. "The Knowledge Graph is Google's system for organizing information about millions of well-known "entities": people, places, and organizations in the real world".[caption id="attachment_608" align="aligncenter" width="572"]

Google uses this graph to improve users’ searches since 2012 / Image courtesy of Google[/caption]Google uses this graph to improve users’ searches since 2012, when they were offering results for more than 500 million objects, or 3.5 billion facts. They use it in three scenarios:
- When people are searching; to show the ideal option.
- The best summaries; only show the most relevant information.
- Less-known information, but also relevant; this data completes the best summaries.
Moreover, this resource is being used on Google Now.On the other hand, it’s relevant highlighting that Google gets the data from public and private sources, including Wikipedia results. And that they allow institutions or companies to personalize their own data. Through your official website, you can personalize your logo, company contact number and social profiles.Lastly, Google is working on the potential successor of Knowledge Graph, Knowledge Vault. This also takes into account unstructured information sources.
The Phone Graph
The expansion of smartphones has created a new resource, the phone graph. Our lives revolve around mobile phones, and our phone contacts make up our most accurate social network.In our phone address books, we generally have the contact information of people really close to us. This feature raises the viability of the relationships the phone graph can show. Besides this, another key point is that we have contacts of real people in our phones.[caption id="attachment_609" align="aligncenter" width="600"]

Every day more apps need our phone number and contacts to offer their services[/caption]In this sense, the phone graph might be one of the most relevant social maps in few years, as every day more apps need our phone number and contacts to offer their services. Standing out amongst them are Whatsapp (900 million monthly active users worldwide), Snapchat (Nearing 200 Million Active Users, in June 2015) and recently, Periscope (2M daily active users).---------Additional data: we wouldn’t like to finish without talking about the citation (link) graph, the concept cited by Larry Page and Sergey Brin in their thesis "The Anatomy of a Large-Scale Hypertextual Web Search Engine". In this valuable document, they present “Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext”. :)